A simplified version of the problem goes like this: Imagine that you are imprisoned in a tunnel that opens out onto a precipice two paces to your left, and a pit of vipers two paces to your right. To torment you, your evil captor forces you to take a series of steps to the left and right. You need to devise a series that will allow you to avoid the hazards — if you take a step to the right, for example, you’ll want your second step to be to the left, to avoid falling off the cliff. You might try alternating right and left steps, but here’s the catch: You have to list your planned steps ahead of time, and your captor might have you take every second step on your list (starting at the second step), or every third step (starting at the third), or some other skip-counting sequence. Is there a list of steps that will keep you alive, no matter what sequence your captor chooses?
Category: Statistics
Big Data’s Mathematical Mysteries
At a dinner I attended some years ago, the distinguished differential geometer Eugenio Calabi volunteered to me his tongue-in-cheek distinction between pure and applied mathematicians. A pure mathematician, when stuck on the problem under study, often decides to narrow the problem further and so avoid the obstruction. An applied mathematician interprets being stuck as an indication that it is time to learn more mathematics and find better tools.
I have always loved this point of view; it explains how applied mathematicians will always need to make use of the new concepts and structures that are constantly being developed in more foundational mathematics. This is particularly evident today in the ongoing effort to understand “big data” — data sets that are too large or complex to be understood using traditional data-processing techniques.
Our current mathematical understanding of many techniques that are central to the ongoing big-data revolution is inadequate, at best. Consider the simplest case, that of supervised learning, which has been used by companies such as Google, Facebook and Apple to create voice- or image-recognition technologies with a near-human level of accuracy. These systems start with a massive corpus of training samples — millions or billions of images or voice recordings — which are used to train a deep neural network to spot statistical regularities. As in other areas of machine learning, the hope is that computers can churn through enough data to “learn” the task: Instead of being programmed with the detailed steps necessary for the decision process, the computers follow algorithms that gradually lead them to focus on the relevant patterns.
In Defense Of The Gaussian Copula
The Gaussian copula is not an economic model, but it has been similarly misused and is similarly demonised. In broad terms, the Gaussian copula is a formula to map the approximate correlation between two variables. In the financial world it was used to express the relationship between two assets in a simple form. This was foolish. Even the relationship between debt and equity changes with the market conditions. Often it has a negative correlation, but other times it can be positive.
That does not mean it was useless. The Gaussian copula provided a convienent way to describe a relationship that held under particular conditions. But it was fed data that reflected a period when housing prices were not correlated to the extent that they turned out to be when the housing bubble popped. You can have the most complicated and complete model in the world to explain asset correlation, but if you calibrate it assuming housing prices won’t fall on a national level, the model cannot hedge you against that happening.
Warren Buffett: Oracle or Orang-utan?
Buffett has taken the criticism from these fellow giants of finance in his stride, responding with trademark wit and humour. He even compared himself to an orang-utan flipping coins. Joking aside, this is a testable hypothesis: Is Buffett’s performance better than chance? To test it, we will stand on the shoulders of another giant: Jacob Bernoulli.
• • •
Again it is a very small number, but we can use our formula to calculate its value:
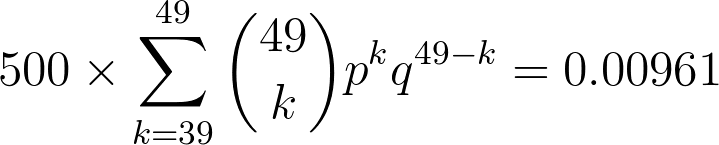
The expected value is much smaller than 1, so we can conclude that Buffett is a better investor than the luckiest orang-utan. If stock returns really do follow a random process – as Eugene Fama asserted – then Warren Buffett is more than just lucky. Compared with his competitors in the S&P 500, he’s brilliant.
Angus Deaton: A Statistician’s Economist
Many different themes run through Deaton’s work – one of which is an emphasis on the importance of measurement. In his view, data collection and economic theory have become too separated, to the advantage of neither the data collector nor the economic theorist. Collectors need the guidance of theory and analysts need to understand the data they work with. Too often, Deaton says, “what we think we know about the world is dependent on data that may not mean what we think they mean”.
